
[ad_1]
Resources are sufficient for far-field voice recognition, where the user is metres away from the microphone. Voice-controlled digital home assistants and automotive infotainment are intended applications.
Why process speech on the local PCB?
“Neural network-based speech recognition algorithms are performing more tasks locally, rather than in the cloud, due to concerns of latency, privacy and network availability,” said Cadence.
Called HiFi 5, it has twice the audio processing capacity and four-times the neural network (NN) processing of the earlier HiFi 4 DSP.
“Our aim is to make a large vocabulary engine available locally that is capable of processing natural language,” Cadence marketing director Gerard Andrews told Electronics Weekly. “We surveyed open-source speech-recognition neural networks, and we designed HiFi 5 to run those types of network.
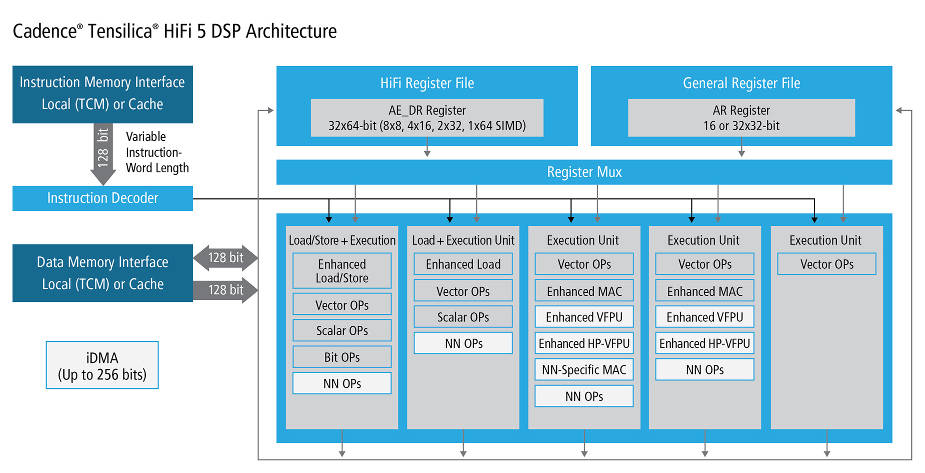
Processing elements include:
- Five very long instruction word (VLIW)-slot architecture capable of issuing two 128-bit loads per cycle
- DSP multiplier-accumulators:
Support for 8 32x32bit MAC/cycle or 16 16x16bit MAC/cycle
Optional eight single-precision floating-point MACs per cycle - Neural network-multiplier accumulators:
32 16×8 MAC/cycle or 16×4 MAC/cycle
Optional 16 half-precision floating-point MACs per cycle
The DSP MACs, according to Andrews, include, for example, support for saturation, while the neural network MACs are optimised for multiplying a vector value by a matrix. “In so many neural networks, you end up spending a huge amount of time multiplying a vector by a matrix,” he said, adding that: the choice of how many MACs to include, and what data types and weight lengths to support, was based on work with HiFi 4 customers.
Floating point maths has been incorporated for two use cases – single precision for the vocal front-end for beam formation and echo-cancellation, and half-precision for some neural networks. “Floating point gives a quick time-to-market,” said Andrews. “For example, if you develop something floating point in MatLab, converting it to fixed-point is quite time-consuming.”
The multiplier support 8bit weights because “the big trend is to quantise down to 8bit weights for speech recognition, which does not have to trade off too much in accuracy. You do see papers presented where people are trying to go down to 4bits,” said Andrews. “We anticipate that most algorithms will take advantage of our 16x8bit multiplier: 16bits for data from the microphone and 8bits for the weights.”
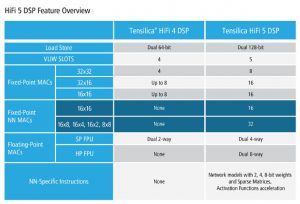
For other weighting schemes, 4bit, 2bit and 1bit operation is available as well as 8bit.
Ambiq Micro, producer of microcontrollers built on ‘sub-threshold’ silicon processes to save power, was the first HiFi 5 customer.
“To meet the extremely difficult challenge of bringing computationally intensive neural network-based far-field processing and speech recognition algorithms to energy-sensitive devices, Ambiq Micro chose to be the first silicon licensee of Cadence’s HiFi 5 DSP”, said Ambiq v-p of marketing Aaron Grassian. “Porting the HiFi 5 DSP to Ambiq Micro’s sub-threshold power-optimised platform enables product designers, ODMs and OEMs to take the most advantage of technology from audio software leaders like DSP Concepts and Sensory by adding voice assistant integration, command and control, and conversational UIs to portable, mobile products without sacrificing quality or battery life.”
Supporting the intellectual property, there is a library of optimised library functions commonly used in neural network processing – especially for speech processing. These functions are aimed at integration within popular machine learning frameworks.
HiFi 5 is also compatible with the firms library of existing audio and voice codecs, and audio enhancement software packages, optimised for earlier versions of the firm’s HiFi product range.
[ad_2]
Source link