
[ad_1]
Called Furian, in 8XT guise it will produce 35% more Gflop/mm2 and a 80% improvement in fill-rate/mm2 compared with the top-end implementations of the existing (Rogue 7XT) architecture – both on the same semiconductor process and clocked at the same frequency. 70-90% real-world gaming density improvement is claimed.
Other changes suite Furian better to smaller process geometries, and improve its compatibility with machine learning and artificial intelligence algorithms.
 “Applications such as virtual reality and augmented reality and convertibles require higher graphics resolutions and frame rates, and emerging applications such as ADAS [automated driving] and machine intelligence require increased compute efficiency. Devices for these applications are often designed in sub-14nm process technologies,” said the Imagination. “Furian addresses these needs through a multi-dimensional approach to performance scalability, with an extensible design and a focus on easy system integration and layout in the latest processes. With Furian, embedded products will be able to deliver high-resolution, immersive graphics content and data computation for sustained time periods within mobile power budgets.
“Applications such as virtual reality and augmented reality and convertibles require higher graphics resolutions and frame rates, and emerging applications such as ADAS [automated driving] and machine intelligence require increased compute efficiency. Devices for these applications are often designed in sub-14nm process technologies,” said the Imagination. “Furian addresses these needs through a multi-dimensional approach to performance scalability, with an extensible design and a focus on easy system integration and layout in the latest processes. With Furian, embedded products will be able to deliver high-resolution, immersive graphics content and data computation for sustained time periods within mobile power budgets.
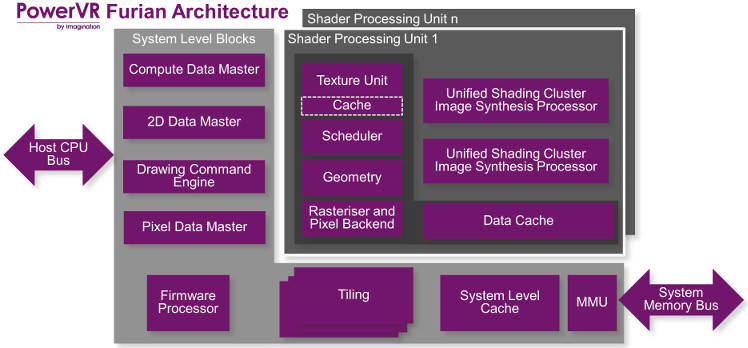
One of the big changes is that Imagination has to a more distributed architecture.
“Rogue was a little bit like a hub structure where everything talked to everything else through what we called the Hub, which was the interface to the memory structure,” Imagination business development director Kristof Beets told Electronics Weekly. “With Furion, we have limited the number of blocks that talk to each other. It is a lot more hierarchical. Control is more like the leaves of a tree structure.”
The distributed approach is why Furian is better suited to smaller geometries than Rogue – It has fewer long bus runs, and long metalisation runs are disproportionately resistive in lower process nodes, said Beets.
Another difference is that cache is no longer unified, but spread around the architecture in smaller blocks. For example, each shader processing unit gets its own data cache, and its own texture unit cache. “There is far less cache thrashing,” said Beets.
Whereas in Rogue 2D image handling for user-interface displays required data to be converted to 3D and then processed, it is now processed in a dedicated 2D block (2D Data Master in diagram) that talks to the texture unit. “You don’t want to be wasting power doing a 3D operation when it is actually a simple 2D task,” said Beets.
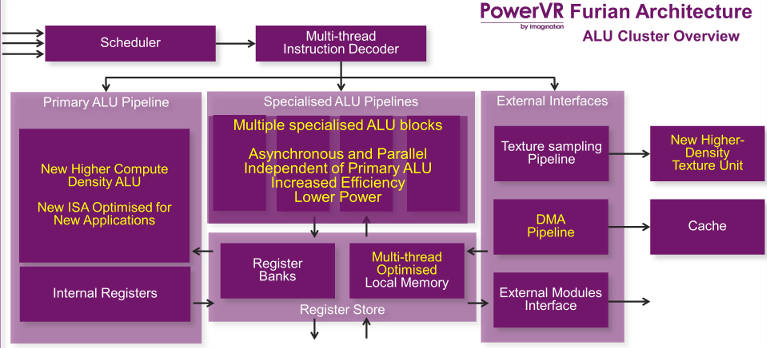
The ALU has come in for a lot of scrutiny.
Operations have been split into two completely independent pipelines (see top diagram), a primary one for massively-parallel multiply-and-add, and, to prevent this from being interrupted, a specialised pipeline for everything else – sine, cosine, reciprocal and square root, for example.
 In each Rogue pipeline (now a Furian’s primary pipeline) there were two multiply-accumulate (MAD) blocks, which could only be used together if incoming data has two lots of independent data. “We were struggling to use the second MAD as a pipelind is only working on one pixel,” said Beets.
In each Rogue pipeline (now a Furian’s primary pipeline) there were two multiply-accumulate (MAD) blocks, which could only be used together if incoming data has two lots of independent data. “We were struggling to use the second MAD as a pipelind is only working on one pixel,” said Beets.
In Furian, the second MAD has been replaced by a simple multiplier, which according to Beets saves so much die area that twice as many pipelines can be fitted in almost the same area as one Rogue pipeline. “We are seeing a 90% throughput improvement,” he said. In total Furian has 32 primary ALU pipelines, compared to 16 in Rogue.
For pure computation, APIs including OpenCL 2.0, Vulkan 1.0 and OpenVX 1.1* are provided with a bi-directional GPU/CPU coherent interface for efficient data sharing, and a transition to user mode queues from kernel mode queues which reduces latency and CPU utilisation for compute operations, said Imagination.
Furian intellectual property has been licensed to multiple customers and initial RTL has been delivered. The first GPU core variants based on Furian will be announced in the middle of this year.
[ad_2]
Source link